Australia’s Most Effective Digital / Specialist Agency – 3 consecutive years

Potential Realised.
We’re a growth agency.
We see every business not as they are, but what they could be.
Pinpointing the right levers for profitable growth across the entire customer journey.
We see every business not as they are, but what they could be.
Pinpointing the right levers for profitable growth across the entire customer journey.
Who we are
An independent group focussed on building effectiveness.
Every business is different. And every business has different goals. This simple truth inspires us to make the AFFINITY Group different.
While others define themselves by their outputs – advertising, media, brand, CX, CRM, digital transformation, etc – we define ourselves by our impact.
Sure, we make what others do. But where we start is by using data to identify the important moments between you and your audience, then optimising and connecting the experiences that matter.
It’s not only helped us consistently deliver business-transforming outcomes. It's the reason we’ve been named by WARC Effective 100 as Australia's most effective digital/specialist agency for four years (2017, 2018, 2019, 2021).
Whether you have a vague idea of where you want to be, or a concise long-term vision, our mantra – Thinking first, Egos last, Outcomes always – will help you achieve it.
Read moreWhile others define themselves by their outputs – advertising, media, brand, CX, CRM, digital transformation, etc – we define ourselves by our impact.
Sure, we make what others do. But where we start is by using data to identify the important moments between you and your audience, then optimising and connecting the experiences that matter.
It’s not only helped us consistently deliver business-transforming outcomes. It's the reason we’ve been named by WARC Effective 100 as Australia's most effective digital/specialist agency for four years (2017, 2018, 2019, 2021).
Whether you have a vague idea of where you want to be, or a concise long-term vision, our mantra – Thinking first, Egos last, Outcomes always – will help you achieve it.
What we can do for you
Brand & Creative
Human behaviour is at the heart of everything we do.
- Brand Launches & Refresh
- B2B & B2C Campaign Development
- Brand & Corporate Identity Design
- Creative Territory Development
- Brand Architecture
Media
A strategic approach that can make all the difference to success.
- Media planning
- Media Buying
- Digital Buying – Premium, Exchange, Retargeting
- Performance - PPC, SEM, SEO
- Campaign Optimisation & Reporting
Customer Experience
Understand your customers and you’ll understand what matters to them.
- Customer Journeys
- CX Measurement
- CRM Strategy and Campaigns
- Service Design
- New Product Development
- Lead Generation & Prospect Nurture
Digital & Technology
Aligning technology and creative solutions into real-world design
- Digital Strategy
- Website Design and Development
- Mobile / App Development
- Business System Integration
- CRM & Martech Implementation
- Digital Transformation
Data & Research
The power of data underpins everything we do
- Data Mining & Advanced Analytics
- Predictive Modelling
- Multivariate Positioning Tests
- Qualitative and Quantitative Research
- Benchmarking/ Tracking
- Behavioural Design
- Stakeholder Consultation/ Engagement
Our work
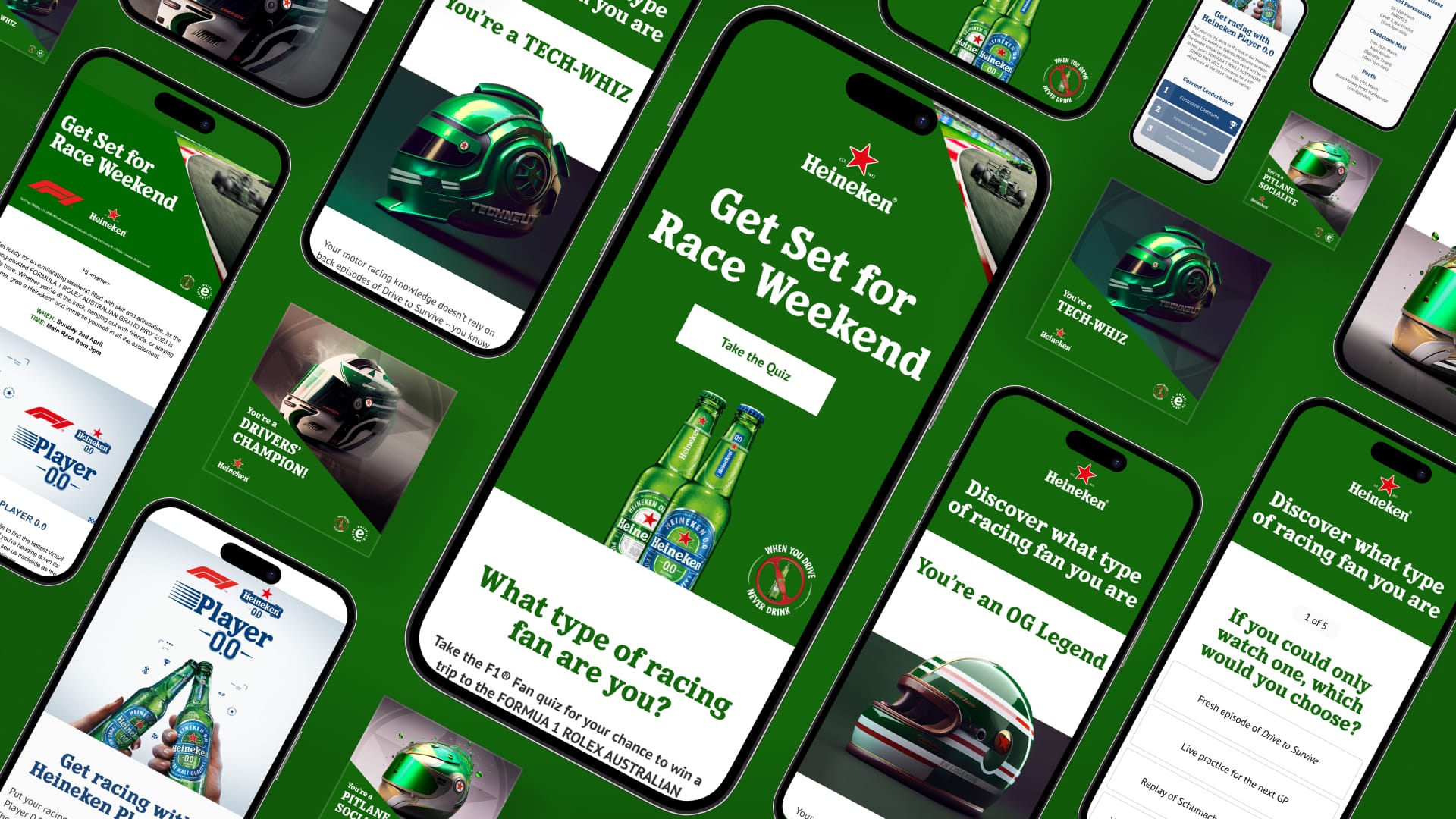
LION - XXXX Beer
How brand social can compete with native social with just an iPhone 15
View case studyWorley
Turning a company’s ambition into reality through a ground up brand transformation
View case study





Would you like to see more of our thinking?
See more workSubscribe to our thinking
Sign up to the AFFINITY Group newsletter.
Blog


Crocs to Sippy Cups
March 22, 2024

From Jawbreakers to Rule Breakers
March 22, 2024

Calculated Craziness
March 21, 2024

Who Cares About Brand Safety Anymore?
February 13, 2024

Hungry For Risk?
February 9, 2024
Would you like to read more?
Read moreNews



This year AFFINITY's worked with Worley on a full global rebrand, and we're proud it's now featured on Mumbrella.
Mumbrella – November 28, 2023

AFFINITY's sustainability focused rebrand for our client Worley was also featured on B&T
B&T – November 28, 2023

AFFINITY's new Worley rebrand, which focuses on sustainability, is featured on Mediaweek
Mediaweek – November 28, 2023
Checkout our full news feed for all the latest AFFINITY happenings
Read more newsContact us
Get in touch and find out what we can do for you.
Business hours: 9–5.30pm, Monday–Friday
Call Luke on:
+61 2 8354 4400
"*" indicates required fields
Our associations and partnerships



